This is a third part about mass data run in SAP Sales/Service Cloud. It contains information about mass data runs’ optimization.
The main problem, which you can face, is execution time. If mass data run processes a huge amount of records, execution time increases quickly (not linear). Execution time is limited to 10 hours. There are different ways to solve this issue.
Let’s have a look at them:
Optimize your code.
You can use standard functionality “Run Performance Check”. This check can be useful sometimes.
Check result is shown in picture 1.
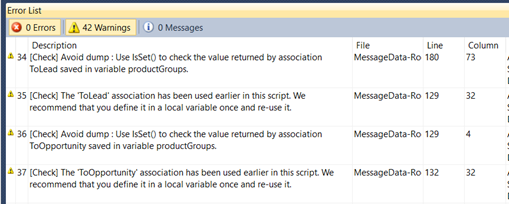
Picture 1 – Performance check result
There is a very good article about performance optimization and I strongly recommend you to read it: https://blogs.sap.com/2016/05/12/performance-best-practice-with-mass-enabled-event/.
Summarized information from this article:
- Don’t store a lot of logic in standard events, especially After-Modify. This event slows down system performance and MDR performance (if you update retrieved data). After-Modify can trigger events in other business objects and lead to a long call chains. Use Before-Save, it is possible there, instead of After-Modify;
- Don’t use long chains of association navigation. Store the intermediate result into variable and use variable to a further navigation;
- Don’t use auto-generated queries (QueryByElements) for custom BO, create your custom queries;
- Use Query.ExecuteDataOnly where possible;
- Avoid nested loops.
Package data processing.
Mass data run execution time grows up not linear, that’s why package processing is the best way to improve performance. The main idea is to split a huge amount of records in smaller packages and process them in parallel or in a sequence.
There are two possible situations:
1) Selection parameters for splitting into packages exist. Example: update fields into customers. Customers are assigned to some sales organizations. MDR with selection parameter “Sales Organization ID” has been created. Separate run with filled parameter “Sales Organization ID” should be created for each sale organization.
In general: create separate run for every package of data and plan them in parallel or in sequence (picture 2). Data in every package shouldn’t intersect.
Recommended: selection parameter should split data in almost equal packages.
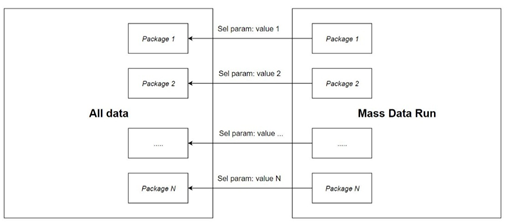
Picture 2 – Split into packages using selection parameters
2) Selection parameters for splitting into packages don’t exist. Example: update customers’ fields. Customers are assigned to one sale organization and separate runs with selection parameter “Sales Organization ID” can’t be created. We still can use case 1 if some other parameters for splitting exist.
If such parameters don’t exist we can do the following:
1. Mass data run processes data from one package and reschedules itself using ABSL. Data will be processed in sequence. We should add additional fields to BO: MDR id, start row, package size.
BO:
businessobject PackageProcessing {
[Label("Package ID")] element PackageID: ID; // Additional for selection
[Label("MDR id")] element MDR_ID: ID;
[Label("Start row")] element StartRow: IntegerValue;
[Label("Package size")] element PackageSize: NumberValue;
action ProcessPackage;
}
Action:
import ABSL;
import AP.Common.GDT;
import AP.FO.BusinessPartner.Global;
import AP.PlatinumEngineering; // For scheduling MDR from ABSL
// Const
var PACKAGE_SIZE = 200; // Default value for package size, can be reset
var MDR_NAME = "MDR_NAME"; // MDR object in studio, ex. MultifunctionalMDR
var DELAY_SECONDS = 30;
// Set package size
var packageSize;
if(!this.PackageSize.IsInitial()){
packageSize = this.PackageSize;
}else{
packageSize = PACKAGE_SIZE;
}
// Get some data from custom BO and sort by customer id
var query = СustomBO.QueryByElements; // Custom query will be quicker
var selParams = query.CreateSelectionParams();
var sortParams = query.CreateSortingParams();
sortParams.Add(СustomBO.CustomerID);
// Get package, execute not from DB, as we need to change some data
var result = query.Execute(selParams, sortParams, packageSize, this.StartRow);
// Do something this package (data in variable "result")
...
// Reschedule mass data run
if(result.Count() > 0){
// Set technical data for next iteration
this.StartRow = this.StartRow + packageSize;
// Additional: set selection parameter for MDR
// Needed if created in UI run had selection parameters
var queryParam: QueryParameter;
queryParam.ParameterName = "PackageID";
queryParam.Sign = "I";
queryParam.Option = "EQ";
queryParam.Low = this.PackageID;
// Time parameters
var currentTime = Context.GetCurrentGlobalDateTime();
var delayDuration = Library::Duration.Create(0,0,0,0,0, DELAY_SECONDS);
var mdrStartTime = currentTime.AddDuration(delayDuration);
// Fill MDR data
var MDRO_ID : XPEString;
MDRO_ID = this.MDR_ID;
MDRO.AddSelectionParameter(MDR_NAME, "", "PackageID", MDRO_ID, queryParam);
// Plan MDR
MDRO.ExecuteDateTime(MDR_NAME, "", mdrStartTime, MDRO_ID);
}
// Reset start row
else{
this.StartRow = 0;
}
By this way you can easily select and process data for custom BO. We can’t do the same as queries for standard business objects don’t have sorting parameters.
Action for standard BO will look like:
import ABSL;
import AP.Common.GDT;
import AP.FO.BusinessPartner.Global;
import AP.PlatinumEngineering; // For scheduling MDR from ABSL
// Const
var PACKAGE_SIZE = 200; // Default value for package size, can be reset
var MDR_NAME = "MDR_NAME"; // MDR object in studio, ex. MultifunctionalMDR
var DELAY_SECONDS = 30;
var STATUS_ACTIVE = "2";
// Set package size
var packageSize;
if(!this.PackageSize.IsInitial()){
packageSize = this.PackageSize;
}else{
packageSize = PACKAGE_SIZE;
}
// Set start and end
var start = this.StartRow;
var end = start + packageSize;
// Customers query
var query = Customer.QueryByBusinessObjectCustomer;
var selParams = queryCustomer.CreateSelectionParams();
selParams.Add(query.LifeCycleStatusCode, "I", "EQ", STATUS_ACTIVE);
var result = query.ExecuteDataOnly(selParams).OrderBy(n => n.InternalID);
var counterCustomers = 0;
foreach(var customer in result){
// 1...n, not 0...n as in index array
counterCustomers = counterCustomers + 1;
// Skip processed records
if(counterCustomers < start){
continue;
}
// Stop as needed package was processed or processed last record
if(counterCustomers >= end || counterCustomers == resultCustomer.Count()){
break;
}
// Retrieve
var customerInstance = Customer.Retrieve(customer.InternalID);
// Do something this package data
...
}
// Reschedule mass data run
if(result.Count() > 0 && result.Count() – end > 0){
// Reschedule in the same way
}
// Reset start row
else{
this.StartRow = 0;
}
Retrieving data by this way is slower, than retrieving concrete package from DB. However, this code will work more quickly than processing and saving a huge amount of data per one execution.
Sum up:
- Package processing helps us process data more quickly and more efficiently;
- We shouldn’t worry about 10 hours limit, as for every package separate run will be created;
- All rows from DB will be processed (schedule run once again if data exists);
- Data will be processed in sequence;
- Only one run should be planned.
2. Create N runs to process data from concrete intervals. Number of run is: divide number of rows in DB by package size. Data can be processed in parallel or in sequence, it depends on how runs will be scheduled. This is the processing of data using selection parameters, where parameters are a start row and package size. (picture 3).
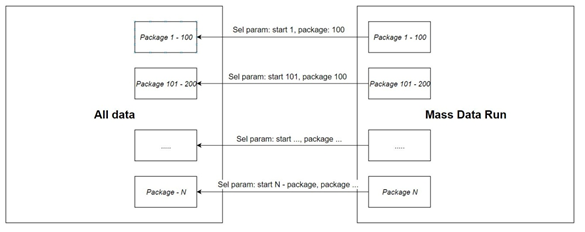
Picture 3 – Split into packages using special selection parameters
BO will have the same structure as for package processing and rescheduling. Action – the same structure, except rescheduling.
Sum up:
- All runs should be scheduled manually;
- For every package separate run should be created and scheduled;
- New runs should be added if number of records in DB increase;
- Only rows selected in run will be processed, needed packages can be restarted;
- Runs can process data in parallel or in sequence.
Thank you for attention!
Subscribe